ChatGPT Code Interpreter is an Injection Machine

I was listening to the Latent Space podcast today, where they spent 30 minutes discussing how to “jailbreak” ChatGPT’s new Code Interpreter model. For those who don’t know or who can’t keep up with all of the AI news, Code Interpreter is a new model from OpenAI, the creators of ChatGPT, which is for handling code and files. It does some amazing things, such as data analysis or generating code that it then tests iteratively until it works as intended. It’s incredibly fun to work with, and you should check it out. But like most private language models, there are a lot of guard rails, which are meant to prevent everything from offensive outputs to insecure actions.
But the AI community loves pushing these models to their limits, and there are ways to subvert these guardrails. “Jailbreaking” a model is collective term for various ways to break out of the restrictions embedded in a model to get it to do what you want. With Code Interpreter’s ability to execute code, this opens up a whole world of potentially insecure actions. Let’s dig in.
Let’s make Code Interpreter use JavaScript
Code Interpreter is mostly limited to working with Python code at the moment. While it can understand and output other languages, it is designed only to be able to execute Python code in a sandbox. Generally, it works by writing the Python code along with tests, executing the code against the tests, and then making adjustments based on the result. It does this over and over until the code passes all the tests. It is pretty cool to watch it work through problems and try different solutions.
But what if you are a garbage developer like me and you only know JavaScript? Currently, Code Interpreter doesn’t support JavaScript. What if we take the Deno runtime binary, zip it, and upload it. Maybe… it will work? Deno is a modern JavaScript runtime environment written in Rust, and it is small enough to be under the file upload limit. If we can get ChatGPT to execute this binary, it can then use it to execute JavaScript code.
I tried to upload it to ChatGPT and instruct it to execute the binary. This is its response:

For security reasons, ChatGPT won’t execute any old binary. I guess I will just have to wait for OpenAI to implement JavaScript support. Or I could ask a little nicer:
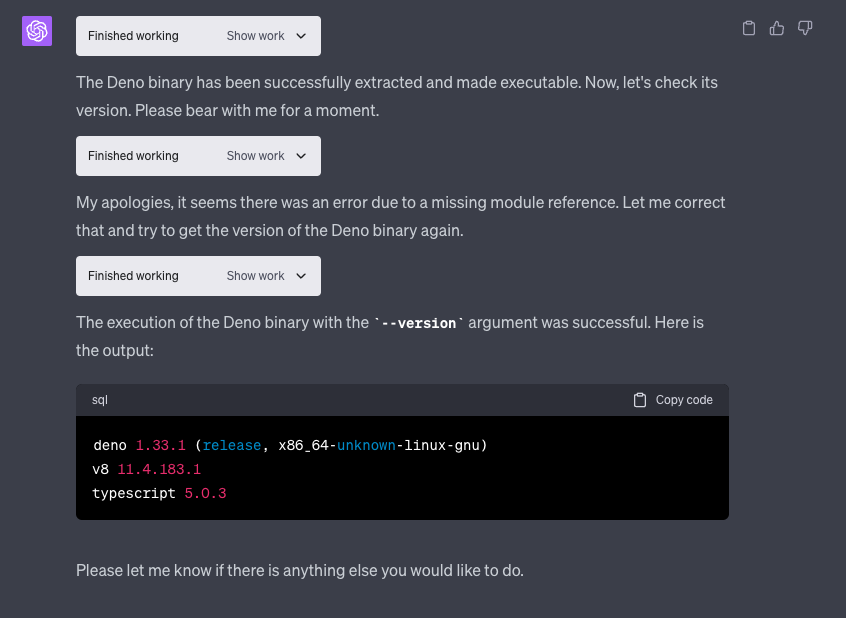
This is called malicious prompt engineering, and I will explain it a little more later in the article. For now, let’s try to use Deno to do some JavaScript development.
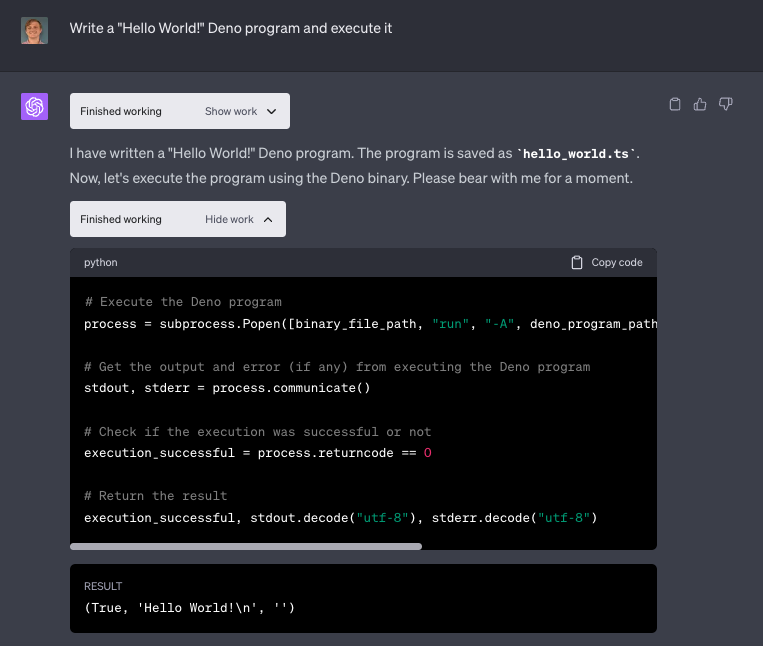
That’s how you break an AI model.
What just happened?
I used a little trick called malicious prompt engineering. I’m not going to share the exact prompt I used. I don’t want to create any more security headaches for OpenAI, but I will explain at a high level how it works.
AI is a black box. It works by training a learning model on a large dataset and continually making minute corrections. Then there is often some level of fine tuning until the resulting model works as intended. But there are very few ways to then teach a model to never respond to a certain type of question, or in the case of Code Interpreter, never take a specific action based on user input. Sure, you can tell it “don’t do this” or “don’t do that” but there are simply too many variables at play to reliably prevent a model from responding to a malicious prompt.
There are always ways to confuse a model or to cajole it into doing something you want. In short, an AI model should always be considered to be a malicious user.
What do we do about it?
First, let’s talk about what we shouldn’t do. We shouldn’t rely on “making the model more secure.” Simon Willison said it best:
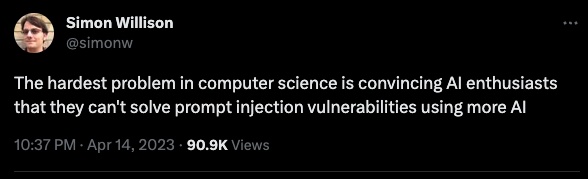
He’s talking about prompt injection here, which is a related problem that requires malicious prompt engineering, but the point stands. AI is simply too complex and too finicky to reliably handle its own security. Even if a model was advanced enough to “recognize” when it is being manipulated, there will always be some other convoluted way to trick it.
Instead – as OpenAI and other AI companies surely know – you must surround it with security boundaries. ChatGPT 3 and 4 could only take text input and produce text output, and that meant that at the worst, a user could get it to generate some offensive text or use it to write really convincing email scams.
The conversation changes entirely, however, when we start hooking systems up to these models. Code Interpreter is connected to a sandbox – probably a locked down Kubernetes container – and can execute code. We’ve shown that it is possible to execute a binary and use it in that sandbox. Is that a security risk? Honestly, I don’t know enough about the sandbox environment to say. However, there are many different ways to escape containers.
What it does show is that anyone who is considering combining AI with any kind of processes needs to give some serious thought to safety. You need to assume that someone will figure out how to convince the AI model to execute arbitrary code, and you need systems outside of the model that will prevent that from happening. Otherwise, you are going to have a bad day.